导语:一个耗时 6 个月的科研项目,产生了数十 GB 的技术文档、实验数据和分析报告,但项目结束后,这些宝贵的知识资产却陷入了”数据孤岛”。更严重的问题是,新团队成员正在重复已解决过的技术难题,而相关的解决方案和经验教训就存储在某个难以定位的目录中。这种”知识断层”现象在科研机构中普遍存在:据统计,每年完成的数万个科研项目中,超过 90% 的项目资料在结项后失去了有效的检索和复用能力。如何通过智能化的知识管理技术,将这些沉睡的数据资产重新激活,实现组织知识的有效传承和复用?

一个熟悉的场景
李教授最近很头疼。
学校要求他总结过去三年的科研成果,准备申报新的重点实验室。他知道这三年做了很多有价值的项目,但是…
- 项目 A 的核心算法:存在某个硬盘里,具体哪个已经记不清了
- 项目 B 的数据集:当时的研究生毕业走了,账号都注销了
- 项目 C 的合作方案:在某个邮件附件里,但邮箱里有几千封邮件
- 项目 D 的实验结果:记得很有突破性,但具体数据找不到了
三天后,李教授终于拼凑出了一份申报材料,但他心里很清楚:那些真正有价值的东西,大部分都找不回来了。
这样的场景,在每个高校、每个科研院所都在重复上演。
资料”死亡”的三大原因
1. 存储方式:各自为政的”信息孤岛”
现状:
- 张老师习惯用百度网盘
- 李同学喜欢存本地硬盘
- 王研究员偏爱 OneDrive
- 项目组用的是学校统一的文件服务器
结果:项目结束后,资料散落在各个角落,没有统一的”地图”。
2. 组织方式:缺乏统一的”语言”
现状:
- 同一份材料,每个人的命名方式不同
- 文件夹结构各有各的逻辑
- 缺少标签和分类体系
- 版本管理混乱
结果:即使找到了文件,也不知道哪个是最终版本,哪个是有用的。
3. 传承机制:人走茶凉的”断层”
现状:
- 项目负责人调岗或退休
- 核心成员毕业离校
- 没有知识传承的制度安排
- 新人重新摸索,重复造轮子
结果:宝贵的经验和教训无法传承,组织记忆出现断层。
这些”死”资料的真实价值
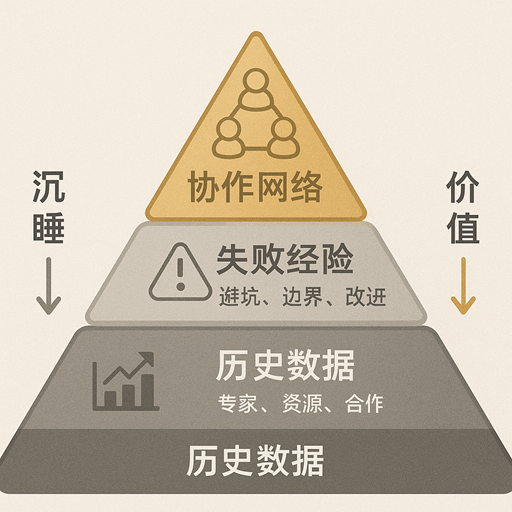
很多人觉得项目资料”过时了就没用了”,这是一个巨大的误区。
历史数据的价值
- 趋势分析:多年数据可以看出发展规律
- 对比验证:新方法需要历史基准来证明效果
- 异常识别:历史正常值帮助识别当前异常
失败经验的价值
- 避坑指南:前人踩过的坑,后人可以绕过
- 边界条件:失败案例往往揭示方法的适用边界
- 改进方向:失败原因分析指向优化路径
协作网络的价值
- 专家图谱:谁在哪个领域有经验
- 资源地图:哪些设备、数据、渠道可以复用
- 合作历史:成功的合作模式可以复制
让资料”活”起来的三个关键
1. 统一存储:建立”组织大脑”
不是简单的文件服务器,而是智能知识库
- 语义化存储:不只是存文件,还要存文件的”意义”
- 自动标签:AI 自动识别文件类型、主题、关键信息
- 关联网络:相关资料自动建立连接,形成知识图谱
举个例子:
当你搜索”深度学习”时,系统不仅能找到标题包含这个词的文件,还能找到内容相关的所有资料——算法代码、实验数据、论文草稿、会议记录等。
2. 智能检索:从”人找信息”到”信息找人”
- 传统方式:记住文件名 → 找到文件夹 → 打开文件
- 智能方式:描述需求 → AI 理解意图 → 精准推荐
实际应用场景:
- 输入:”去年做的图像识别准确率是多少?”
- 系统返回:相关项目报告、实验数据、对比分析
- 输入:”类似的合作模式还有哪些?”
- 系统返回:历史合作案例、成功要素分析、联系方式
3. 主动传承:让经验”自己说话”
被动传承:新人问老人,老人凭记忆回答
主动传承:系统主动推送相关经验和注意事项
智能传承机制:
- 情境感知:识别当前工作场景,推送相关历史经验
- 专家推荐:遇到问题时,推荐最有经验的内部专家
- 最佳实践:自动总结成功项目的共同特征
一个”活”起来的案例
某 985 高校计算机学院的转变
改造前:
- 10 年积累了 500 多个项目
- 资料分散在 200 多个文件夹中
- 新项目启动时,80%的时间在找资料
- 类似问题重复解决,效率低下
改造后(引入知识图谱+RAG 系统):
- 所有项目资料统一入库,自动建立关联
- 智能问答系统,3 秒内找到相关资料
- 新项目启动时,系统自动推荐相似项目经验
- 重复性工作减少 60%,创新时间增加 40%
具体效果:
- 李教授现在申报项目:系统自动生成过往成果总结,数据准确、逻辑清晰
- 新入职的王老师:通过智能推荐,快速了解学院研究方向和合作资源
- 在读博士生小张:遇到技术难题时,系统推荐了 3 年前类似项目的解决方案
技术实现:并不复杂的”复活术”
很多人觉得这种智能化改造很复杂,其实核心技术已经相当成熟:
1. 文档解析与理解
- OCR 技术:扫描件也能识别和搜索
- NLP 处理:理解文档的主题和关键信息
- 多模态融合:文字、图表、音频统一处理
2. 知识图谱构建
- 实体抽取:自动识别人名、项目名、技术名词
- 关系建立:分析实体之间的关联关系
- 图谱更新:新资料自动融入现有知识网络
3. 智能问答系统
- 意图理解:理解用户的真实需求
- 检索优化:在海量资料中精准定位
- 结果排序:按相关性和重要性排序
- 最关键的是:这些技术可以渐进式部署,不需要推倒重来。
开始行动:三个可行的第一步
第一步:资料大盘点(1-2 周)
- 统计现有资料的分布情况
- 识别最有价值的”沉睡”资料
- 制定优先级:哪些先救活
第二步:建立统一标准(2-3 周)
- 设计文件命名规范
- 建立分类标签体系
- 制定版本管理制度
第三步:技术改造试点(1-2 个月)
- 选择一个重要项目作为试点
- 部署基础的智能检索功能
- 收集用户反馈,持续优化
写在最后
项目会结束,但知识应该永生。
每一份资料都承载着研究者的心血,每一个数据都可能是未来突破的线索。让这些宝贵的知识资产”死”在硬盘里,不仅是资源的浪费,更是对创新的阻碍。
真正的数字化转型,不是把纸质文件变成电子文件,而是让沉睡的数据变成活跃的知识,让分散的经验变成系统的智慧。
当我们的项目资料不再”死去”,而是在知识图谱中”永生”时,每一次新的探索都站在了巨人的肩膀上。这才是科研和创新应有的传承方式。
关于作者:专注于高校科研信息化建设,在知识图谱、RAG 技术、数据资产化等领域有丰富实践经验。如果您对项目资料的智能化管理感兴趣,欢迎交流探讨。